


")
Banana.dev established itself as a pioneer in the serverless GPU space, designed to solve the “cold start” problem for massive machine learning models.
Introduction
For AI startups and independent developers, the biggest hurdle to a successful launch is often the infrastructure. High GPU costs and the technical debt of managing servers can kill a product before it finds its audience. Banana.dev entered the market with a radical promise: pay only for the milliseconds your model is running, with near-instant wake-up times. Now fully integrated into Replicate, this technology allows developers to deploy production-ready AI models with just a few lines of code. By eliminating the need for server maintenance and providing elastic scaling that responds to traffic in real-time, Banana’s core tech ensures that your application remains responsive and cost-effective, whether you have ten users or ten million.
Serverless GPU
Ultra-Fast Cold Starts
Pay-per-Second
Replicate Integrated
Review
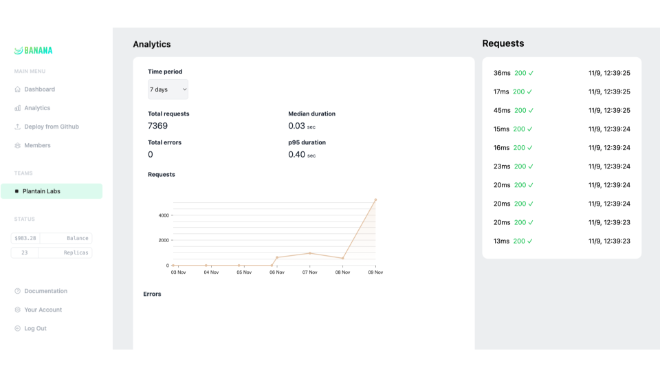
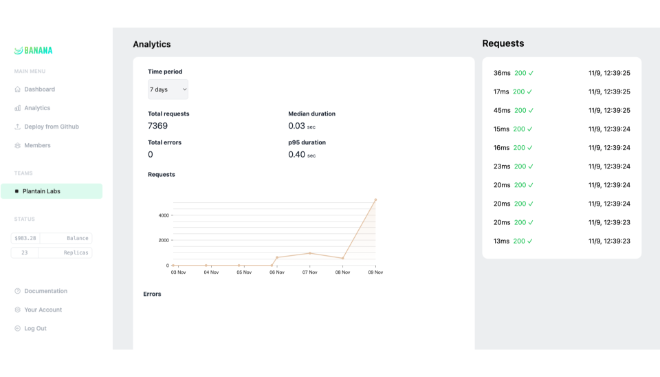
Banana.dev established itself as a pioneer in the serverless GPU space, specifically designed to solve the “cold start” problem for massive machine learning models. By building a specialized virtualization layer, Banana enabled developers to deploy models like Stable Diffusion, Whisper, and Llama with initialization speeds up to 10x faster than traditional cloud providers. The platform became a favorite for developers who needed to scale from zero to thousands of concurrent requests without managing complex Kubernetes clusters or paying for idle hardware.
In a significant industry consolidation in early 2024, Banana.dev was acquired by Replicate, a move that combined Banana’s ultra-fast optimization technology with Replicate’s massive model library and developer ecosystem. While the standalone Banana platform has been integrated into the Replicate infrastructure, its legacy lives on through the lightning-fast cold starts and seamless “Infrastructure-from-Code” experience now available to Replicate’s million-plus users. For engineers seeking the spiritual successor to Banana’s speed, the technology now powers the backend of one of the world’s most robust AI deployment platforms.
Features
Zero-Management Infrastructure
Deploy models without ever configuring a server, managing a Docker registry, or setting up auto-scaling rules.
Optimized Cold Starts
Custom virtualization technology ensures that models "wake up" and begin processing in seconds, rather than minutes.
Framework Agnostic
Supports any machine learning framework, including PyTorch, TensorFlow, and Hugging Face, through a unified deployment process.
Pay-per-Second Billing
Completely eliminates the "idle GPU tax" by charging only for the active execution time of your functions.
Global Edge Execution
Models are deployed across a distributed network of high-performance GPUs (NVIDIA A100s, H100s) to minimize latency for global users.
One-Line API Integration
Once deployed, models are accessible via a simple HTTP endpoint, making them easy to integrate into web and mobile applications.
Best Suited for
AI Startup Founders
Launching products with unpredictable traffic where cost-efficiency and instant scaling are critical for survival.
Independent Developers
Prototyping and deploying ML models without the overhead of learning complex DevOps or cloud orchestration.
Software Engineering Teams
Migrating internal AI tools from expensive, always-on instances to a more efficient serverless model.
Generative AI App Builders
Powering image generation, text synthesis, or audio transcription apps that require high-performance GPUs on demand.
Creative Agencies
Building interactive, AI-powered marketing campaigns that experience short-lived but massive traffic spikes.
Bioinformatics Researchers
Running large-scale batch processing for protein folding or genomic sequences in a parallel, serverless environment.
Strengths
Industry-Leading Speed
Extreme Ease of Use
Transparent Pricing
Massive Model Access
Weakness
Standalone Platform Sunsetting
Variable Latency for First Hits
Getting Started with Banana.dev (via Replicate): Step-by-Step Guide
Step 1: Create a Replicate Account
Since Banana has merged, visit Replicate.com and sign up. Your API keys will now be managed through the Replicate dashboard.
Step 2: Choose a Public Model or Upload Your Own
Browse thousands of models (like FLUX or Llama) or use the Cog open-source tool to package your custom model for deployment.
Step 3: Test in the Web Playground
Use the browser-based interface to run a test inference. This allows you to check output quality and measure latency before writing code.
Step 4: Integrate the SDK
Install the Python or JavaScript client (npm install replicate) and call your model using your API token in just a few lines of code.
Step 5: Scale to Production
Deploy your app. The infrastructure automatically handles scaling from zero to hundreds of concurrent GPUs based on your incoming request volume.
Frequently Asked Questions
Q: Is Banana.dev still a standalone company?
A: No, Banana.dev was acquired by Replicate in early 2024. The teams and technologies have merged to provide a unified AI deployment platform.
Q: Is Banana.dev still a standalone company?
A: Original Banana users have been provided with migration paths to move their custom deployments over to the Replicate infrastructure.
Q: What is a "cold start" in AI?
A cold start occurs when a serverless function hasn’t been run for a while, requiring the system to “spin up” a new container and load the model into the GPU.
Pricing
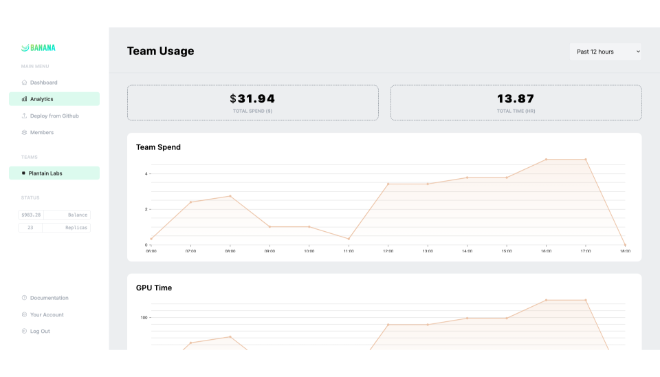
Following the acquisition, Banana’s technology is billed under the Replicate consumption model.
| GPU Type | Use Case | Price per Second (Approx.) |
| NVIDIA T4 | Lightweight inference & testing | $0.00015 / sec |
| NVIDIA A100 (40GB) | Standard production LLM/Image tasks | $0.00045 / sec |
| NVIDIA A100 (80GB) | High-memory models & training | $0.00085 / sec |
| NVIDIA H100 | Frontier model execution & speed | $0.00120 / sec |
Note: You are only billed for the time the GPU is actively processing your request.
Alternatives
Modal Labs
A top-tier competitor offering a similar serverless Python experience with ultra-fast cold starts and Infrastructure-from-Code.
RunPod
A popular choice for teams that want low-cost, on-demand GPU instances with more manual control over persistent storage.
Lambda Labs
Specialized in high-performance GPU cloud rentals, ideal for long-running training jobs rather than serverless inference.
Share it on social media:
Questions and answers of the customers
There are no questions yet. Be the first to ask a question about this product.

Banana.dev
Sale Has Ended