







Modal Labs has emerged as the “undisputed king” of serverless infrastructure for Python-centric AI teams.
Introduction
In the current AI revolution, the bottleneck is no longer just model intelligence, but the speed and cost of deployment. Standard serverless options like AWS Lambda often fail when faced with the heavy GPU requirements and long cold starts of modern ML workloads. Modal Labs solves this by providing an AI-native runtime engineered from the ground up for high-performance autoscaling and instant model initialization. Founded in 2021 by former Spotify and Google researchers, Modal has quickly become the preferred foundation for unicorns like Suno and Quora who need to run millions of executions daily with sub-second latency. By unifying storage, observability, and compute into a single Python-first platform, Modal Labs ensures that AI teams can move from local development to global production in minutes.
AI-Native Runtime
Elastic GPU Scaling
Serverless Python
99% Uptime
Review
Modal Labs has emerged as the “undisputed king” of serverless infrastructure for Python-centric AI teams. Unlike traditional cloud providers that require complex YAML configurations or manual container management, Modal offers an “Infrastructure-from-Code” experience where everything, from hardware requirements to environments, is defined directly in Python. Its custom-built container runtime and scheduler allow for sub-second cold starts, making it 100x faster than traditional Docker-based systems.
The platform is lauded for its elastic GPU scaling, giving developers instant access to thousands of GPUs across major clouds without the need for quotas or reservations. While its usage-based pricing can be difficult to forecast for inefficient scripts, it is often significantly cheaper for bursty workloads, as it scales back to zero the moment code finishes running. For engineers looking to move at “vibe coding” speed, Modal Labs eliminates the DevOps overhead, allowing teams to focus purely on building and scaling high-performance AI applications.
Features
Infrastructure-from-Code
Define your entire environment—including GPU types, CPU cores, and Python dependencies—directly in your code using decorators like @app.function().
Sub-Second Cold Starts
Custom-engineered runtime allows containers to launch and scale in milliseconds, virtually eliminating the "cold start" delay common in serverless platforms.
Programmable GPU Scaling
Access a multi-cloud capacity pool of NVIDIA H100s, A100s, and B200s with intelligent scheduling that ensures availability without reservations.
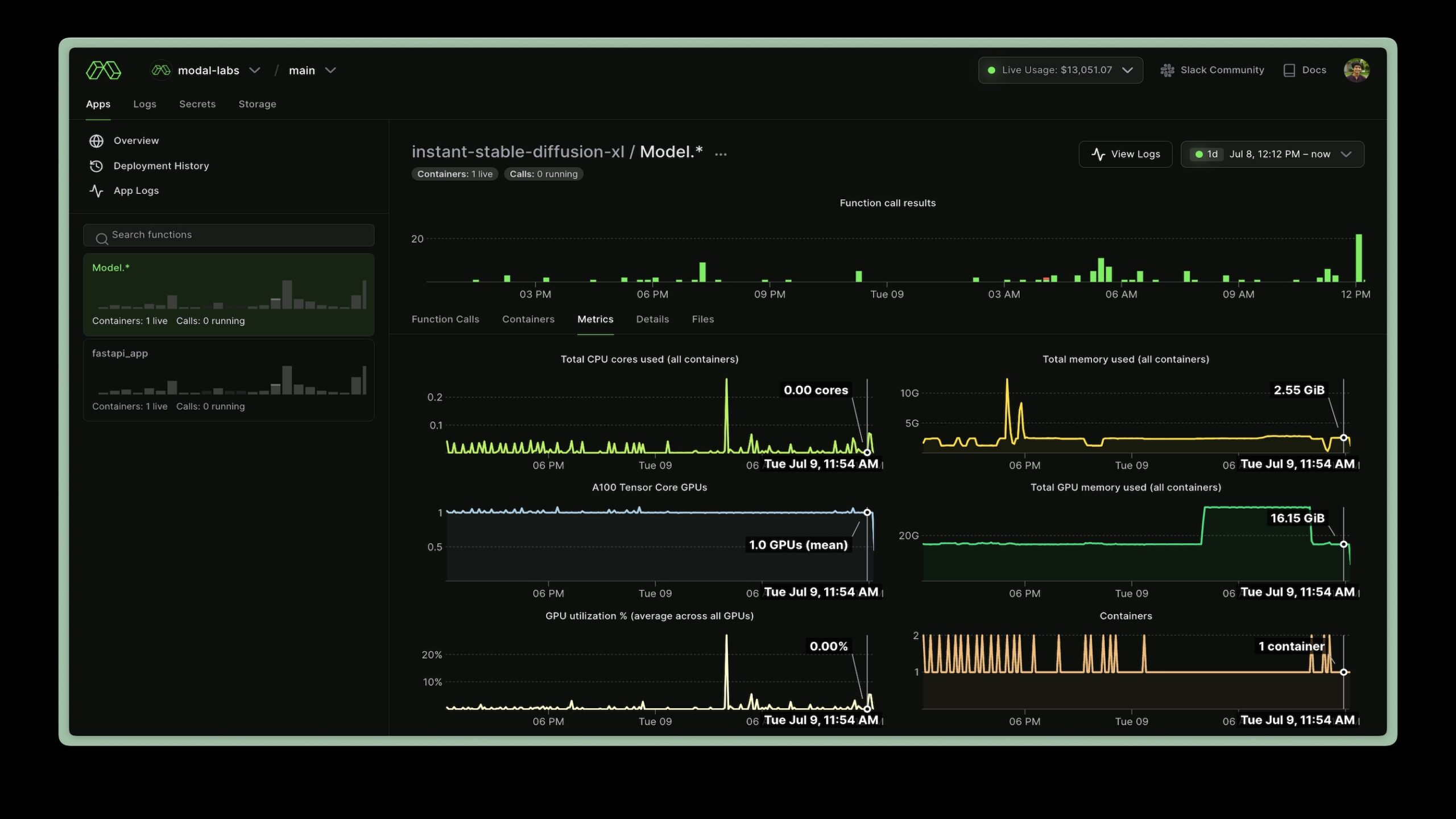
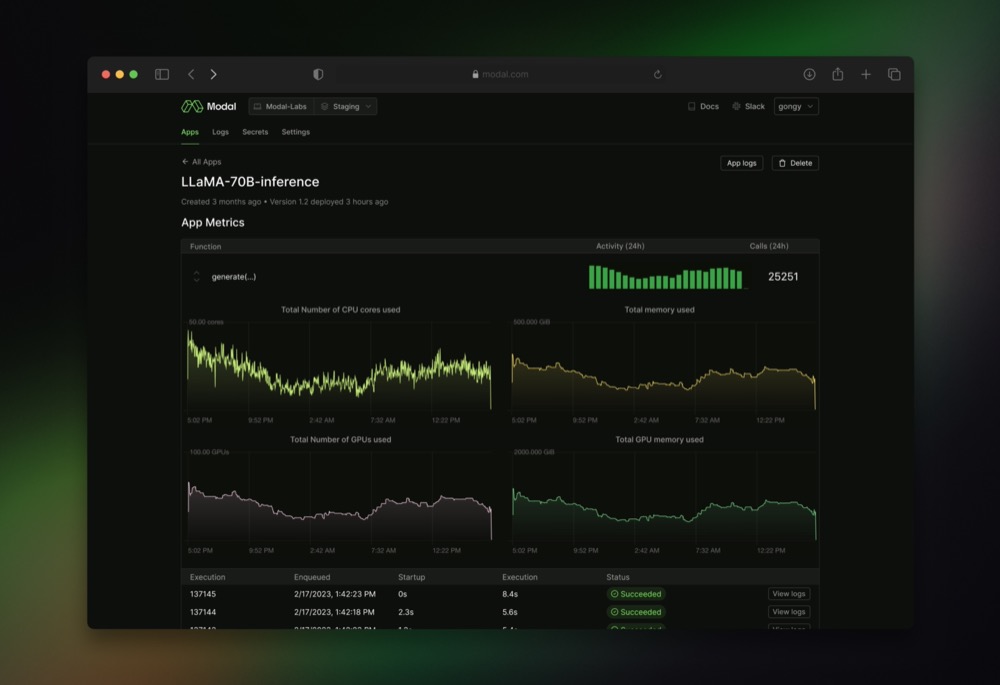
Unified Observability
Features integrated logging, real-time metrics, and interactive cloud shells for live debugging directly inside running containers.
Distributed Storage Layer
A globally distributed filesystem built specifically for high-throughput model loading and fast access to training datasets.
Versatile Workload Support
Handles the entire AI lifecycle, including real-time inference APIs, parallel fine-tuning jobs, and massive batch processing via simple .map() calls.
Best Suited for
AI Engineers & ML Researchers
Scaling Python functions for inference, training, and data processing without managing Kubernetes or Docker.
Full-Stack AI Startups
Rapidly deploying model endpoints and background workers for apps like transcription services or image generators.
Data Science Teams
Running massive parallel batch jobs, such as transcribing thousands of podcasts or embedding huge datasets.
AI Agent Developers
Utilizing secure, sandboxed code execution to safely run untrusted, user-submitted code in isolated containers.
informatics & Protein Folding
Executing compute-intensive models like Boltz-2 or Chai-1 that require high GPU concurrency and fast model loading.
DevOps-Light Organizations
Teams that want to eliminate infrastructure maintenance (YAML, IAM, networking) and focus 100% on product logic.
Strengths
Superior Performance
Seamless Local-to-Cloud DX:
Cost-Efficient Burst Scaling
High GPU Availability
Weakness
Lack of On-Premise Support
Usage Bill Volatility
Getting Started with Modal Labs: Step-by-Step Guide
Step 1: Install and Authenticate
Install the Modal Python package via pip install modal and run modal setup to authenticate your machine with your web account.
Step 2: Define Your App and Image
modal and define an app. Specify your environment (e.g., modal.Image.debian_slim()) and install any necessary AI libraries like torch or transformers.
Step 3: Wrap Functions with Decorators
Add the @app.function() decorator to the Python functions you want to run in the cloud, specifying the required GPU (e.g., gpu="h100") and CPU resources.
Step 4: Execute Remotely or in Parallel
Call your function with .remote() to run a single instance in the cloud, or use .map() to automatically parallelize it across hundreds of containers.
Step 5: Monitor and Deploy
View real-time logs in your terminal as the code executes. Use modal deploy to turn your script into a persistent web endpoint or a scheduled cron job.
Frequently Asked Questions
Q: What is "Infrastructure-from-Code"?
A: It is a paradigm where you define your entire infrastructure (GPUs, memory, OS environment) directly in your Python application, eliminating the need for YAML or external config files.
Q: Does Modal Labs support real-time webhooks?
A: Yes, you can expose any Python function as a secure, scalable HTTPS endpoint by simply adding the @app.webhook() decorator.
Q: Is there a free trial for developers?
A: Yes, the Starter plan includes $30 per month in free compute credits, allowing independent developers to build and scale projects at no initial cost.
Pricing
Modal Labs uses a pay-per-second consumption model combined with tiered subscription plans for higher concurrency limits.
| Plan | Base Monthly Fee | Included Credit | GPU Concurrency |
| Starter | $0 | $30 / month | 10 GPU units |
| Team | $250 | $100 / month | 50 GPU units |
| Enterprise | Custom | Custom | Unlimited / Custom |
Common Compute Rates (per second):
NVIDIA H100: $0.001097 ($3.95 / hour)
NVIDIA A100 (80GB): $0.000694 ($2.50 / hour)
NVIDIA T4: $0.000164 ($0.59 / hour)
CPU (per core): $0.0000131
Alternatives
RunPod
A popular alternative for teams seeking low-cost, on-demand GPU rentals with more manual control over persistent volumes.
Northflank
A production-grade platform for deploying full-stack AI products, offering more control over networking and multi-cloud CI/CD.
AWS Lambda
The established standard for event-driven glue code, though it lacks native GPU support and suffers from high cold-start latency.
Share it on social media:
Questions and answers of the customers
There are no questions yet. Be the first to ask a question about this product.

Modal Labs
Sale Has Ended